Архитектура и сценарии¶
Типовые сценарии использования¶
Сценарий 1: Защита корпоративного чат-бота¶
Компания развернула внутренний чат-бот на базе LLM для сотрудников. AppSec.AIGate устанавливается между фронтендом чат-бота и LLM API. Настраиваются:
- Threat Detection — для блокировки jailbreak-попыток сотрудников.
- PII Detection в режиме
mask— чтобы сотрудники не отправляли клиентские данные в LLM, при этом запрос всё равно доходит до модели (с замаскированными данными). - Content Safety — для блокировки неуместных ответов модели.
- Content Policy типа
blocklist— для запрета обсуждения конфиденциальных проектов по названию.
Сценарий 2: API-шлюз для внешних LLM-провайдеров¶
Компания использует несколько LLM-провайдеров (OpenAI для английского, GigaChat для русского). AppSec.AIGate работает как единая точка входа:
- Настроены два провайдера с разными mapping presets.
- Роутинг по заголовку
X-LLM-Providerнаправляет запросы к нужному backend. - Единый профиль безопасности применяется ко всем провайдерам.
- SIEM-экспорт отправляет все события в корпоративный Splunk.
Сценарий 3: Соответствие 152-ФЗ¶
Организация обязана защищать персональные данные по 152-ФЗ. AppSec.AIGate обеспечивает:
- PII Detection в режиме
block— запросы с персональными данными блокируются полностью. - Output PII Detection — перехватывает случаи, когда LLM возвращает ПДн в ответе.
- Data Retention с
pii_scrub— автоматическое удаление ПДн из логов по истечении срока хранения. - Compliance Reports типа
pii_dlp— регулярные отчёты для предоставления регулятору.
Сценарий 4: Режим наблюдения при пилотном запуске¶
Перед включением блокировки в продакшене организация хочет оценить, как система будет работать. AppSec.AIGate запускается в Monitor Mode:
- Все детекторы работают и генерируют события.
- Ни один запрос не блокируется — пользователи не затронуты.
- Команда безопасности анализирует события и тюнит пороговые значения.
- После калибровки Monitor Mode отключается и система начинает блокировать реальные угрозы.
Сценарий 5: Интеграция с внешними LLM Gateway (LiteLLM, Portkey)¶
Клиент уже использует LLM Gateway (LiteLLM, Portkey, Kong AI Gateway) для маршрутизации запросов к множеству LLM-провайдеров. AppSec.AIGate подключается как guardrail backend — гейт проверяет запрос перед LLM и ответ после.
В этом режиме AppSec.AIGate работает не как прокси, а как webhook-сервис:
- LLM Gateway Adapter (
llm-gateway-adapter) принимает webhook-вызовы от внешнего Gateway в его native-формате (LiteLLM Generic Guardrail API, Portkey Webhook). - Адаптер транслирует вызов на канонический scan-эндпоинт
api-gateway(/_aigate/v1/adapters/litellm), указывая профиль явно через заголовокX-AIGate-Profile-ID. - Запрос идёт через ту же
fan-out → detectors → PDPпайплайну, что и в Сценариях 1–3. - Решение возвращается обратно в формате, который понимает внешний Gateway:
ALLOW→{"action":"NONE"}(LiteLLM) /{"verdict": true}(Portkey) — LLM Gateway продолжает запрос;BLOCK→{"action":"BLOCKED", "blocked_reason": <reason>}(LiteLLM) /{"verdict": false, "error": <reason>}(Portkey) — LLM Gateway блокирует;SANITIZE:- LiteLLM:
{"action":"GUARDRAIL_INTERVENED", "texts":[masked]}— LLM Gateway подставляет замаскированный prompt и продолжает запрос с маскированным текстом; - Portkey:
{"verdict": false, "error": <reason>}— Portkey не поддерживает text-substitution на guardrail-уровне, поэтомуSANITIZEмапится в блокировку, идентичнуюBLOCK. Для Portkey-сценария рекомендуется политика без SANITIZE-исходов (только ALLOW/BLOCK) либо принять SANITIZE-как-block как осознанный trade-off.
- LiteLLM:
Архитектура потока (LiteLLM):
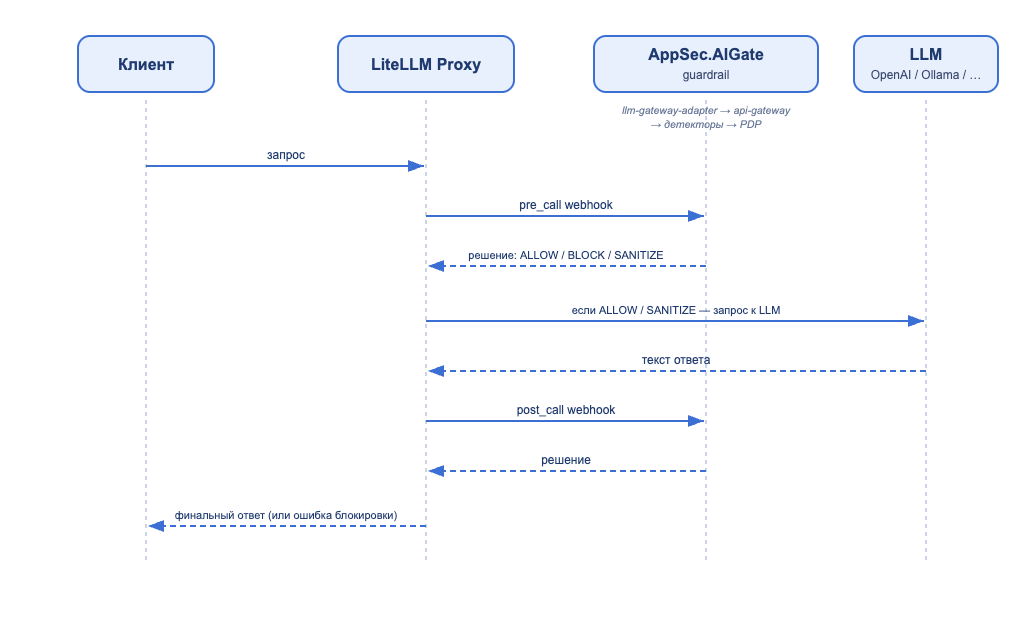
Отличия от Сценариев 1–3:
- AppSec.AIGate не проксирует LLM-трафик — клиент продолжает пользоваться своим LLM Gateway.
- Админ создаёт в AppSec.AIGate профиль типа
scan_onlyи указывает егоprofile_idв адаптере (ADAPTER_AIGATE_PROFILE_ID) — фиктивный guardrail-провайдер не нужен. - Адаптер реализует fail-secure контракт: при недоступности api-gateway запрос блокируется — клиент защищён от утечек через fail-open.
- Подробнее: Интеграция с LiteLLM.
Архитектура обработки запроса¶
Два режима входа — reverse-proxy и guardrail
Схема ниже описывает reverse-proxy режим (Сценарии 1–4): клиент шлёт LLM-трафик через AppSec.AIGate, который проксирует его в LLM backend. Для guardrail-режима (Сценарий 5: интеграция с внешним LLM Gateway — LiteLLM, Portkey) поток выглядит иначе — клиент остаётся на своём LLM Gateway, а AppSec.AIGate подключается как webhook-сервис через адаптер llm-gateway-adapter. Подробнее: Сценарий 5 выше и Интеграция с LiteLLM. Pipeline проверок (детекторы, PDP, decisions ALLOW/BLOCK/SANITIZE) одинаков для обоих режимов.
Схема ниже показывает путь запроса и ответа через все компоненты AppSec.AIGate:
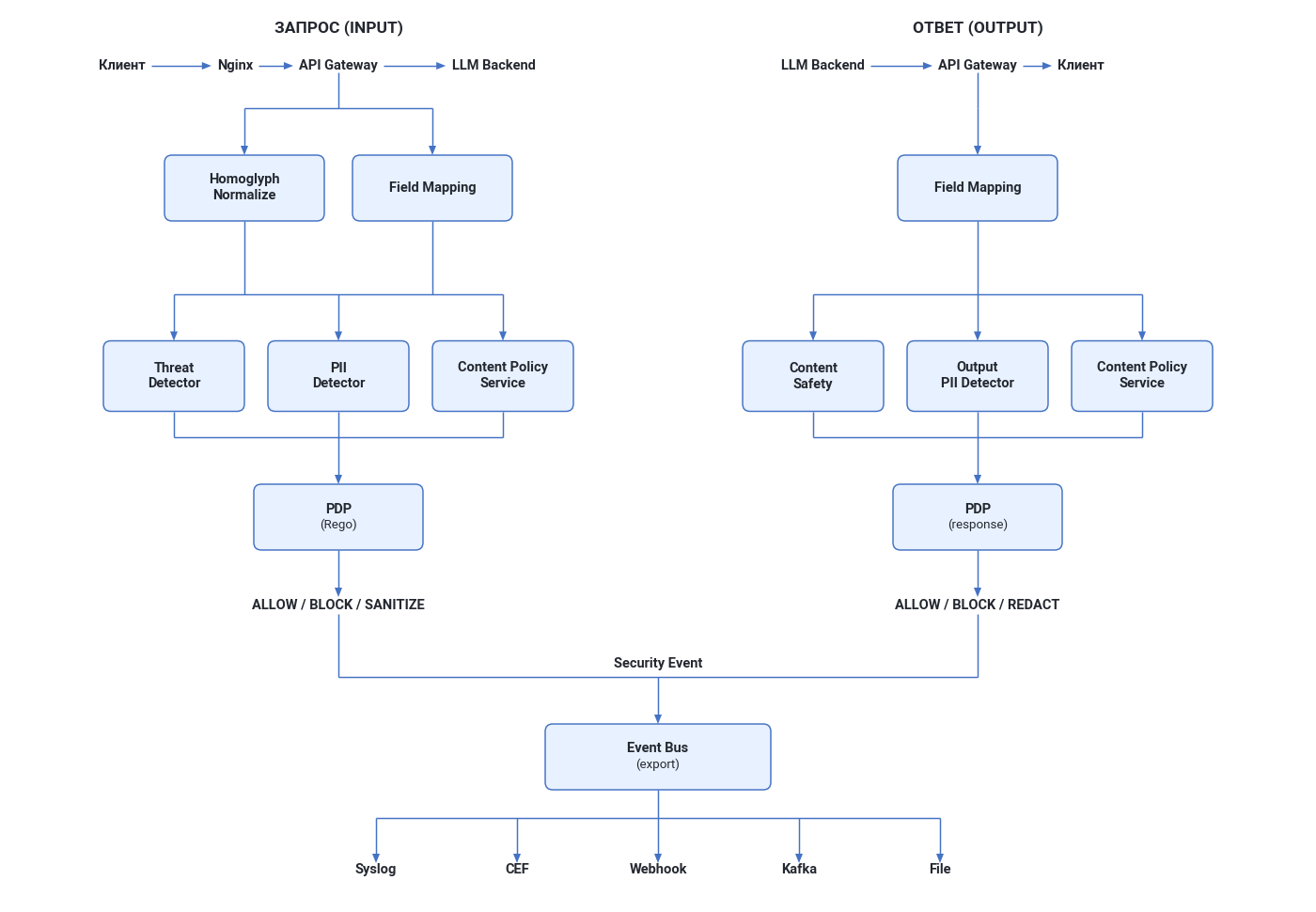
Пояснение к схеме:
-
Nginx — точка входа. Перенаправляет трафик к API Gateway на основе конфигурации маршрутов (см. Настройка перенаправления трафика).
-
Field Mapping — API Gateway определяет, какому провайдеру принадлежит запрос (по URL, хосту или заголовку), и через mapping preset извлекает пользовательский промпт из структуры запроса.
-
Homoglyph Normalize — нормализация текста для защиты от unicode-обфускации. Применяется до всех детекторов.
-
Параллельная детекция (Input) — три детектора работают одновременно:
- Threat Detector — ML-классификация safe/unsafe.
- PII Detector — обнаружение персональных данных.
- Content Policy Service — проверка по кастомным правилам.
-
PDP (Policy Decision Point) — движок принятия решений на базе Rego. Собирает результаты всех детекторов и принимает финальное решение:
- ALLOW — запрос безопасен, передать к LLM.
- BLOCK — запрос опасен, вернуть ошибку клиенту.
- SANITIZE — PII обнаружены, замаскировать и передать к LLM.
- MONITOR — угроза обнаружена, но система в режиме наблюдения — пропустить, создать событие.
-
Параллельная детекция (Output) — три детектора для ответа LLM:
- Content Safety — ML-классификация по категориям (8 на запросах, 7 на ответах).
- Output PII Detector — поиск секретов и технических данных.
- Content Policy Service — проверка ответа по правилам (если scope =
outputилиboth).
-
Event Bus — все события безопасности отправляются во внешние системы через настроенные экспортеры.
Двусторонняя инспекция¶
AppSec.AIGate проверяет трафик в обоих направлениях. Это принципиально важно, потому что угрозы существуют с обеих сторон: пользователь может отправить опасный запрос, а LLM может вернуть опасный ответ.
Входящий запрос (Input) — защита LLM от пользователя¶
| Шаг | Действие | Цель |
|---|---|---|
| 1 | Определение провайдера по маршруту | Понять, к какому LLM направлен запрос |
| 2 | Извлечение user prompt через field mapping | Получить текст промпта из структуры API-запроса |
| 3 | Homoglyph-нормализация текста | Нейтрализовать unicode-обфускацию |
| 4 | Перевод RU→EN — опциональный шаг, по умолчанию отключён | Принудительный прогон RU-контента через ML-детекторы. Включается переменной GATEWAY_TRANSLATION_ENABLED=true; по умолчанию выключен, т.к. Threat Detector корректно обрабатывает русский без перевода |
| 5 | Параллельная детекция: Threat + PII + Content Policy | Три проверки одновременно для минимальной задержки |
| 6 | Решение PDP: ALLOW / BLOCK / SANITIZE / MONITOR | Финальное решение на основе всех детекторов |
Исходящий ответ (Output) — защита пользователя от LLM¶
| Шаг | Действие | Цель |
|---|---|---|
| 1 | Извлечение текста ответа через field mapping | Получить сгенерированный текст из структуры ответа LLM |
| 2 | Параллельная детекция: Content Safety + Output PII + Content Policy | Три проверки одновременно |
| 3 | Решение PDP: ALLOW / BLOCK / REDACT | Финальное решение: пропустить, заблокировать или вырезать секреты |
Важно
Детекторы на входе и выходе — разные. На входе работают Threat Detection и PII Detection (защита модели и данных), на выходе — Content Safety и Output PII Detection (защита пользователя и инфраструктуры). Content Policy может работать в обоих направлениях.